7W - 쿠버네티스의 스케줄링, 커스텀 스케줄러 설정
개요
이번 문서에서는 쿠버네티스의 스케줄링에 대해서 알아보고, 이에 대한 설정법들을 알아본다.
기본적으로 사용되는 테인트, 어피니티, 토폴로지 스프레드 등은 개념만 다루고 실습을 진행하지 않는다.
이 문서는 어디까지나 CKA를 취득할 정도로 쿠버네티스에 대한 역량을 가진 사람을 대상으로 삼기 때문이다.
대신 커스텀 스케줄러를 직접 만드는 방법을 간단하게 다룬다.
참고로, 커스텀 스케줄러를 만들긴 했으나 처음 의도한 전략을 구현하는 데에는 실패했음을 밝혀둔다.
사전 지식
스케줄링이란
스케줄링은 어떤 노드에 파드를 배치하도록 결정을 내리는 동작을 말한다.
스케줄링에 있어서 고려할 것들은 무엇이 있을까?
- 고가용성 - 여러 노드에 골고루 파드 배치
- 효율성 - 연관성이 깊은 파드들을 같은 노드에 배치
- 자원 분배 - 특정한 자원이 있는 노드는 특정한 파드만 배치
- 보안 - 크리티컬한 파드는 다른 노드로 분리, 혹은 네트워크 트래픽이 외부로 나가지 않게 만들기
클러스터를 운영하는데 있어 관리자는 다양한 지점에서 스케줄링이 일어나도록 고려해야할 필요가 있다.
기본적으로 쿠버네티스에서 제공하는 스케줄링 로직이 존재하나, 여기에 관리자는 다양한 설정을 하여 스케줄링을 제어할 수 있다.
이 문서에서는 전체적인 스케줄링 구조, 기본적으로 제공되는 스케줄링 기법, 스케줄링을 확장하는 기법들을 정리한다.
스케줄링 흐름
파드를 만들라는 명령을 내리면 kube-apiserver는 etcd에 해당 오브젝트에 대한 내용을 저장한다.
파드가 실제로 어떤 노드에서 실행되기까지, 어떤 과정이 일어나는가?
여기에서 가장 첫 번째로 관여를 하게 되는 컴포넌트가 바로 kube-scheduler이다.
api서버는 단순하게 파드의 정보를 etcd에 저장만 할 뿐이다.
api 서버가 저장한 파드 정보에는 기본적으로 노드에 배치된다(assigned)는 정보가 없다.
스케줄러는 이러한 파드가 있는지 감시하다가, 파드가 어떤 노드에서 실행되는 것이 적합한지 결정을 내리는 동작, 즉 스케줄링을 한다.
스케줄링은 크게는 두 가지 단계로 나뉜다.
필터링(filtering)
이 단계는 어떤 노드들이 배치될 만한지를 선별하는 단계이다.
여기에서 선택된 노드들을 실행 가능한(feasible) 노드라고 부른다.
만약 이 단계에서 남은 노드가 없다면, 해당 파드는 정말 어딘가에 배치될 수 없다는 것을 뜻한다.
스케줄러는 이런 파드를 unschedulable이라고 상태를 업데이트한다.
스코어링(scoring)
선별된 노드들 중에서 어떤 노드가 파드를 실행하기 가장 적합한지 점수를 내는 단계가 스코어링 단계이다.
여기에서 가장 높은 점수를 얻는 노드가 최종적으로 선택된다.
만약 1등 점수를 가진 노드가 여러 개라면 노드는 무작위로 선택될 것이다.
바인딩(binding)
이걸 스케줄링의 하나의 단계라 보기는 조금 어려운데, 스케줄링이 완료되고 일어나는 다음 단계라고 보면 될 것 같다.
아무튼 최종 선택된 노드를 파드 정보에 업데이트하는 동작을 바인딩이라고 부른다.
비로소 파드가 어떤 노드에 들어가게 될지 확정되는 순간이다!
이 개념을 다루는 이유는 나중에 커스텀 스케줄러를 만들 때 이 부분에 대해서도 커스텀이 가능하기 때문이다.
스케줄링 기법
스케줄링을 순전히 스케줄러에게 위임하고 손가락만 빤다면 클러스터를 운영한다고 할 수 없을 것이다.
관리자는 파드, 노드에 다양한 설정을 넣어 스케줄러가 원하는대로 동작하도록 유도하는 게 가능하다.
어떤 파드가 어떤 종류의 노드에 배치되길 희망한다던가(preffered), 제한한다던가(restricted) 하는 설정을 할 수 있다.[1]
nodeName
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx
nodeName: worker1
가장 간단한 방법은 어떤 노드에 배치할지 직접 설정하는 것이다.[2]
보다시피 nodeName을 지정해 대놓고 콕 어떤 노드에 배치하라 지정할 수 있다.
사실 이 경우에는 스케줄링이 된다고 부를 수도 없는 게, 이건 위에서 말한 각종 단계를 거치지 않고 이미 바인딩이 된 것이나 다름없다.
만약 해당 이름을 가진 노드가 없다면?
그냥 파드는 pending 상태로 머물러있다가, 소리 소문 없이 사라져버린다..
해당 노드가 이미 꽉 차있다면?
그럼 파드는 일단 fail이 뜨고, 그 이유가 표시될 것이다.
이에 대한 실습은 E-nodeName으로 스케줄링 실습을 참고하자.
이런 사용방식은 실무 케이스에서 당연히 좋지도 않고, 그럴 거면 쿠버네티스를 쓸 이유도 그다지 없다..
이런 설정을 직접적으로 넣을 수 있도록 디자인된 이유는, 여러 커스텀 스케줄러를 클러스터에서 운영할 경우 관리가 어려워질 때를 위해서이다.
정말 어떤 파드는 확실하게 관리자가 책임지고 컨트롤해야 한다던가 할 때 모든 스케줄링을 우회하도록 하는 건데, 특별한 케이스가 아니라면 그다지 추천되지 않는다.
nodeSelector
nodeSelector:
disktype: ssd
라벨 셀렉터를 이용해 어떤 라벨을 가진 노드에 배치되도록 제한을 걸 수도 있다.
이 경우에는 라벨을 이용해 아주 강력한 필터링이 걸리는 것이라 보면 된다.
kubernetes.io/hostname 라벨은 노드 이름을 나타내니 이걸로 한 노드만 남기고 전부 필터링해버리는 것도 가능하다.
그래도 이건 스케줄링이 걸리긴 하는 거라 위의 nodeName보다는 훨씬 나은 방식이다.
다만, 라벨이란 것은 항상 변형을 할 수 있기도 하고 다양한 클라우드 환경마다 이 값이 항상 노드의 이름을 나타내는 게 아닐 수도 있어서 주의가 필요하다.
affinity
어피니티는 스케줄링 시 사용할 수 있는 대표적인 기법 중 하나이다.
문자 그대로 친화도, 선호도를 나타내는데, 그래서 원하는 노드, 혹은 파드를 선호하게 만들 수 있다.
반대로 안티 어피니티라 하여 꺼리게 만드는 것도 가능하다.
노드 셀렉터와 비교했을 때, 훨씬 표현성이 높기에, 이쪽이 조금 더 유연한 설정이 가능하다.
구체적으로 어피니티는 3가지 유형으로 분류되는데 이들은 양식 작성법이 비슷하면서도 살짝 다르다.
일단 한가지 미리 알아둘 것은 두 필드에 대한 값이다.
- requiredDuringSchedulingIgnoredDuringExecution
- required, 즉 어피니티로서 반드시 요구되는 제약사항을 나타내는 필드이다.
- 스케줄링에 있어 이 값은 필터링으로 작용한다.
- preferredDuringSchedulingIgnoredDuringExecution
- prefer, 즉 어피니티로서 선호를 나타내는 제약사항을 나타내는 필드이다.
- 스케줄링에서는 스코어링으로서 작용하기에, 가중치 값을 넣는 식으로 설정한다.
모든 유형의 어피니티가 이 필드들을 활용하는데, 각 유형에 따라 이것을 설정하는 방법이 조금씩 달라서 자칫 혼동이 오기 쉽다.
이 각 필드를 어떻게 활용하는지는 아래에서 본격적으로 다루겠다.
nodeAffinity
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: topology.kubernetes.io/zone
operator: In
values:
- antarctica-east1
- antarctica-west1
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: another-node-label-key
operator: In
values:
- another-node-label-value
containers:
- name: with-node-affinity
image: registry.k8s.io/pause:3.8
노드 어피니티는 어떤 노드에 배치되도록할지 지정하는 어피니티이다.
파드 스펙에 .affinity.nodeAffinity 필드에 작성한다.
노드 어피니티에 있어 required는 잘 생각해보면 nodeSelector와 비슷하게 동작한다고 보면 된다.
대신 그보다 훨씬 세밀하게 설정을 할 수 있다는 것이 장점이다.
nodeSelectorTerms를 두고 그 아래로 여러 라벨 셀렉터를 넣어줄 수 있는데, 이 원소 간에는 OR 연산이 일어난다.
그리고 그 라벨 셀렉터 안속에 다시 한번 리스트가 들어가는데, 이건 AND 연산이 이뤄진다.
각 리스트에는 라벨 셀렉터로 또 리스트가 들어가면 된다.
전자의 리스트는 OR 연산, 후자의 리스트는 AND 연산이라는 것을 참고하자.
prefer에서는 가중치 값을 weight로 작성한다.
prefer 부분은 nodeSelectorTerms를 뒀던 require와 달리 바로 리스트를 작성한다.
이 리스트에 각각의 조건과 선호도를 작성해주면 된다.
그리고 각 원소의 preference 필드 라벨 셀렉터 하위로 다시금 리스트로 선택할 라벨들을 적어주면 된다.
위와 같이 여기의 라벨 리스트는 AND 연산이 일어난다.
podAffinity & podAntiAffinity
파드 어피니티는 어떤 파드가 있는 노드에 배치되도록 할지 지정하는 어피니티이다.
가령 웹서버 파드는 WAS서버 파드가 있는 노드에 배치돼야 상대적으로 통신이 빠르게 이뤄질 것이다.
그럴 때 이런 식으로 넣어주면 된다.
반대로 파드 안티 어피니티는 어떤 파드가 있는 노드에 배치되지 않도록 할지 지정한다.
이 어피니티들에 대한 설정은 다음과 같은 식으로 해석된다.
Y 기준을 만족하는 파드들이 있는 X 토폴로지를 가진 노드에 배치하도록 하는 어피니티
말이 벌써 어려운데, 일단 Y라는 것은 그냥 파드 라벨에 대한 정보를 적어주는 부분이다.
X가 무엇이냐가 살짝 중요한데, 이것은 노드의 그룹을 나타내는 토폴로지 정보이다.
위 그림처럼 스케줄링에 있어서 먼저 고려되는 것은 토폴로지 정보로, 토폴로지를 기준으로 노드들을 뭉텅이로 취급한다.
그 다음에 비로소 파드의 기준을 따지며 조건을 만족하는 파드가 있는 토폴로지 그룹에 스케줄링을 한다는 것이다.
즉, 노드를 그룹화시켜서 하나로 바라보는 것이 바로 토폴로지라고 보면 되겠다.
그룹화가 되면 실상 한 노드에는 조건을 만족하는 파드가 없더라도 그 노드에 파드가 배치되는 것도 가능한 일이다.
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S1
topologyKey: topology.kubernetes.io/zone
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S2
topologyKey: topology.kubernetes.io/zone
이제 양식 작성법을 볼텐데, 노드 어피니티와 다르게 require에서 nodeSelectorTerms 없이 바로 라벨 셀렉터 리스트가 나온다.
사용 방식 자체는 동일한데, 이번에는 topologyKey라는 필드를 통해 노드 토폴로지를 지정한다.
prefer 부분을 보면 또 골때리는 게, 이번에는 preference가 아니라 podAffinityTerm.labelSelector을 쓴다..
사용법은 똑같으면서도 필드 이름이 달라 상당히 골 때리는데, 스케줄러를 깊이 공부해보면 알게 되겠지만 사실 노드 어피니티와 파드 어피니티는 다른 종류의 플러그인이다.
아무튼 파드 어피니티를 쓸 때 토폴로지키는 필수값이다.
어피니티에는 네임스페이스나 matchLabelKey 같은 다양한 설정들이 존재한다.
심화 설정들은 Affinity 참고.
topology spread contraints
지정한 파드들을 여러 노드에 최대한 분산시켜서 배치하고 싶을 때 거는 설정 방법이다.
가령 10개의 노드가 있는 클러스터에서 디플로이먼트로 10개의 파드를 배치한다고 쳐보자.
이때 상황에 따라 다르겠지만, 이 10개가 한 노드에 배치될 수도 있고, 3개의 노드에만 배치될 수도 있다.
이럴 때 확실하게 노드에 분산 배치되도록 설정하는 것이 바로 토폴로지 분산 제약 방식이다!
사전 지식 - 토폴로지
여기에서 토폴로지를 구태여 자세히 설명하고 있으므로, 나도 여기에 살짝 맞추고자 한다.
토폴로지라고 하는 것은 같은 라벨을 가진 노드의 그룹이다.
클러스터 내에서 노드들을 스펙이나 실제 물리적 위치 등을 고려하여 그룹화를 시켜 활용할 수 있다.
가령 서울 리전에 있는 레디스와 상호작용을 해야 하는 웹서버는 미국 리전보다는 서울 리전에 설치되는 것이 트래픽 비용 절감에 속도 향상도 추구할 수 있을 것이다.
이때, 각 리전의 노드들에 topology.kubernetes.io/region: {리전}이라고 라벨을 붙여준다면?
그럼 이제 topology.kubernetes.io/region 라벨 키를 기준으로 서로 다른 값들을 가진 노드들을 그룹화시킬 수 있다.
이런 식으로 라벨을 기준으로 노드를 나누는 것이 바로 토폴로지이다.
표현은 저마다 다양하지만, 보통 토폴로지의 한 단위 그룹은 도메인이라고도 부른다.
(나는 보통 그냥 한 토폴로지 그룹이라고 표현하는 편이다)
양식 작성법
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
topologySpreadConstraints:
- topologyKey: kubernetes.io/hostname
labelSelector:
matchLabels:
app: test
maxSkew: 1
whenUnsatisfiable: [DoNotSchedule | ScheduleAnyway]
minDomains: 1 # 옵션
matchLabelKeys: <list> # 옵션
nodeAffinityPolicy: [Honor|Ignore] # 옵션
nodeTaintsPolicy: [Honor|Ignore] # 옵션
파드에 topologySpreadConstraints 필드를 이용해 설정할 수 있다.
하위로 리스트를 작성하는 것을 보면 알 수 있듯이, 여러 개의 제약 조건을 걸 수 있다.
각 필드가 무얼 뜻하는지 보자.
- topologyKey
- 노드의 그룹을 나누는 기준이 되는 노드 라벨 키를 말한다.
- 해당 라벨 키에 대해 같은 값을 가지는 노드들은 하나의 그룹으로 묶이며, 이를 도메인이라고 부른다.
- labelSelector
- 분산할 때 고려할 파드들을 매칭하기 위한 라벨 셀렉터
- maxSkew
- 파드가 도메인 간 편향(skew)되게 분포될 수 있는 최대치를 나타낸다.
- 즉, 편향도(skew)는 도메인 별로 분류했을 때 파드 최대 개수 - 파드 최소 개수로 계산된다.
- 이 값이 1이라면, a 노드에 파드가 1개 배치됐다면 다른 노드는 최대 2개까지만 파드를 배치할 수 있다.
- whenUnsatisfiable
- 위의 조건이 충족될 수 없다면 스케줄링을 어떡할지 행동을 지정한다.
- DoNotSchedule의 경우엔 필터링이 걸려 아예 스케줄이 진행되지 않는다.
- ScheduleAnyway의 경우 이 설정은 스코어링으로 여겨지며 높은 값이 매겨진다.
- minDomains
- 여기에서 도메인은 토폴로지로 묶이는 하나의 그룹을 칭한다.
- 그래서 파드가 분산될 때 최소 얼마나 많은 그룹에 분산돼야 하는지를 지정한다.
- whenUnsatisfiable가 DoNotSchedule일 때만 사용할 수 있다.
이 정도 설명만으로는 조금 부족하다고 느껴질 수 있으니, 사용 케이스를 고려해보자.
유즈 케이스

현재 foo: bar이란 라벨이 붙은 파드가 이런 식으로 퍼져 있고 새로운 파드를 하나 띄워야 하는 상황이라 생각해보자.
zone을 토폴로지로 삼을 때, 우리는 새로운 파드가 기왕이면 zoneB에 배치되길 희망한다.
metadata:
labels:
foo: bar
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
foo: bar
그렇다면 이런 식으로 토폴로지 분산 설정을 할 수 있다.
zone을 기반으로 토폴로지를 잡았으니 일단 zoneA와 zoneB가 각 도메인으로 분리된다.
이 상태에서 maxSkew가 1이니, 이제 우리도 파드가 어디에 배치될지 알 수 있다.
- zoneA에 파드가 배치된다면?
- zoneA 파드 3개 - zoneB 파드 1개 = 2
- 즉, 최대편향도값을 넘어버리므로, zoneA에는 배치될 수 없다.
- zoneB에 파드가 배치된다면?
- zoneA 파드 2개 - zoneB 파드 2개 = 0
- 최대편향도값을 넘지 않으므로, zoneB에는 배치될 수 있다!

그래서 새로운 파드는 zoneB에 배치가 될 것이다.
다만 zoneB에 해당하는 노드 중 어떤 노드에 배치될지는 쿠버 조상님도 모른다..
그래서 기왕이면 아무런 파드가 배치되지 않은 노드4에 배치되는 것이 이상적일 것이다!
metadata:
labels:
foo: bar
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
foo: bar
- masSkew: 1
topologyKey: node
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
foo: bar
이럴 때는 이렇게 추가적인 분산 조건을 걸어주면, 각 노드 별로도 토폴로지 그룹이 형성되어 확실하게 노드4로 파드가 배치될 것을 보장할 수 있다!
이렇게 활용할 수 있기 때문에 여러 개의 분산 제약을 걸 수 있도록 디자인된 것이다.

다만, 이런 케이스는 조심할 필요가 있다.
zone으로 분산을 걸기는 하지만 사실 zone마다 노드의 개수가 다를 수 있다.
위의 정책을 그대로 적용하게 된다면, zoneB가 파드가 2개이므로 이쪽에 파드가 배치된다.
그러나 노드 간 최대 편향도는 1을 넘어가면 안되므로 실상 제약 조건 간의 충돌이 일어나 파드가 스케줄링되지 못한다.
이러한 상황을 방지하려면 zone마다 노드 개수가 다를 수 있음을 가정하고 애초에 zone에 대한 maxSkew 값을 조금 더 크게 주는 것이 좋을 것이다.
파드 안티 어피니티와의 비교
분산을 하는 설정을 하는 것은 좋다!
그런데, 이런 설정은 사실 pod AntiAffinity로도 달성할 수 있지 않을까?
topologySpreadConstraints:
- maxSkew: 1
topologyKey: kubernetes.io/hostname
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
app: gitlab-runner
이 설정은 사실..
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: "app"
operator: "In"
values:
- "gitlab-runner"
topologyKey: "kubernetes.io/hostname"
이렇게 파드 안티 어피니티로도 똑같은 효과를 달성할 수 있다.
여기서부터는 조금 내 생각이다.
파드 안티 어피니티와 비교하여 토폴로지 분산 제약의 장점은 maxSkew에 있다.
안티 어피니티를 세팅할 때 require를 이용해 완벽하게 파드들이 떨어지게도 만들 수 있고, 위 예시처럼 prefer를 이용해 가능한 떨어지게 만드는 것도 가능하다.
그러나, prefer를 사용할 때는 weight 값을 얼마나 줘야 할지를 잘 조절해야 하며, 또한 이것은 결국 정말 파드가 분산되는 것을 명확하게 보장할 수는 없다.
반면 토폴로지 분산 제약은 최대 편향도를 지정하여 다른 노드에 비해 한 노드가 지나치게 파드를 배치받는 것을 명확하게 막을 수 있다.
그래서 큰 규모의 클러스터를 운영할 때 관리를 간편하게 하기 위해서는 토폴로지 분산 제약을 사용하는 것이 아무래도 유리하다.
반면 파드 안티 어피니티는 단순하게 한 노드에 두 워크로드를 배치하지 않고 싶을 때 간단하게 사용하기에 좋다.
또한, 현재까지는 파드 분산 제약은 기본적으로 같은 네임스페이스의 파드들만을 대상으로 삼으므로 이럴 때도 안티 어피니티를 사용하는 것이 이점을 가진다.
결론은 둘 다 적재적소에 활용하면 된다!
더 자세한 내용은 Topology Spread Constraints에 담겨있다.
taint & toleration
이건 노드에 얼룩을 칠하고, 이 얼룩을 용인하는 파드만 배치할 수 있도록 필터링 단계를 관리하는 기법이다.
테인트는 노드에 남기는 얼룩(taint)을 말한다.
테인트가 걸리면 아무런 파드가 노드에 배치될 수 없도록 필터링이 걸린다.
파드가 해당 노드에 배치되고 싶다면 해당 얼룩을 용인(toleration)할 수 있도록 명시적으로 설정을 해줘야만 한다.
보통 마스터 노드에는 일반 파드가 배치되지 않는데, 그 이유가 바로 마스터 노드 관련 테인트가 걸려 있기 때문이다.
미리 말하지만, 테인트는 스케줄링에서만 활용되는 게 아니라 이미 존재하는 파드를 축출시키는 것도 가능하다.
(이미 존재하는 파드를 축출하는 것은 스케줄링과 엄연히 다른 개념이니 혼동하면 안 된다.)
노드에 거는 테인트는 크게 세 가지 효과를 설정할 수 있다.
- PreferNoSchedule
- 새로운 파드가 가급적 이 노드에 스케줄링을 하지 못하도록 막는다.
- 즉 스코어링에서 매우 낮은 점수를 받게 만든다.
- NoSchedule
- 새로운 파드가 절대 이 노드에 스케줄링을 하지 못하도록 막는다.
- 이건 필터링 단계로 완벽하게 제어된다.
- NoExecute
- 스케줄링도 막는데, 이미 노드에 배치돼있는 파드들까지 꺼내버린다!
- 이 효과를 용인하지 않는 파드들은 그 즉시 종료되고 다른 노드에 배치될 것이다.
사용법
kubectl taint nodes node1 key1=value1:NoSchedule
사용법은 굉장히 간단하다.
그냥 어떤 노드에 테인트라고 해서 키=값:효과를 적어주면 된다.
같은 키값에 다른 효과를 넣는 것도 가능은 한데, 어차피 NoExecute는 NoSchedule까지 포함하니 굳이 그렇게 사용은 안 한다.
kubectl taint nodes node1 key1=value1:NoSchedule-
없앨 때는 마이너스를 끝에 붙인다.
그렇다면 파드에서 이 얼룩을 용인하려면 어떻게 해야 하는가?
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
---
tolerations:
- key: "key1"
operator: "Exists"
effect: "NoSchedule"
이것도 간단하게, 그저 파드 스펙에 tolerations를 작성하고 어떤 키에 대해 어떤 효과를 용인할지 지정하면 된다.
effect에 단순히 ""를 넣으면 모든 효과들이 용인된다.
tolerations:
- key: "key1"
operator: "Exists"
effect: "NoExecute"
tolerationSeconds: 3600
NoExecute를 용인한 파드는 해당 노드에서 종료되지 않는다.
다만 tolerationSeconds를 지정하면 이 언제까지 용인을 할지 지정할 수 있고, 이 시간을 넘겨서도 노드에 테인트가 있다면 해당 파드도 얄짤 없이 날아간다.
tolerations:
- key: "node.kubernetes.io/unreachable"
operator: "Exists"
effect: "NoExecute"
tolerationSeconds: 6000
만들어진 파드의 yaml을 유심히 뜯어본 사람이라면 이런 값이 있는 것을 볼 수 있다.
이건 승인 제어 단계에서 알아서 주입된 값으로, 노드와의 통신에 잠시 문제가 생겨도 바로 퇴출당하지 않도록 막아준다.
스케줄러 확장
스케줄링은 관리자가 커스텀하고 확장할 수 있도록 플러그인을 넣을 수 있는 구조로 디자인됐다.[3]
그래서 전헤 흐름에서 몇가지 구획을 나눠 확장 포인트를 노출하고 있으며, 이를 이용해 스케줄링을 자유롭게 조정할 수 있다.
이러한 스케줄링의 확장 가능한 아키텍처를 통틀어 스케줄링 프레임워크라고 부른다.
전체 흐름
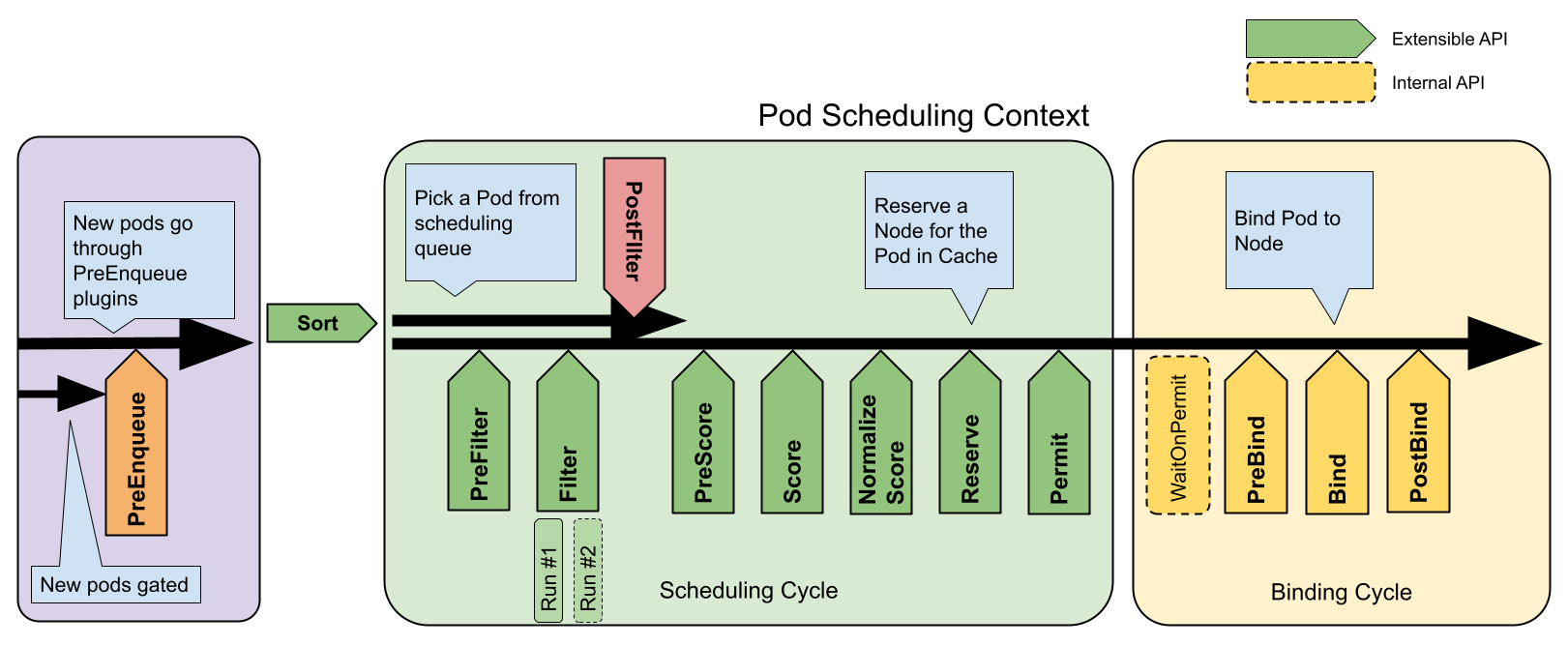
이 사진에 존재하는 각 화살표가 확장 포인트라고 보면 된다.
사실 스케줄링이라는 것은 구조적으로 말하자면, 각 확장 포인트에 여러 스케줄링 플러그인이 주입되어 적용되는 형태인 것이다.
스케줄링 사이클과 바인딩 사이클로 나뉘는데, 이둘을 합쳐 스케줄링 컨텍스트라고 부른다.
스케줄링은 직렬이지만 바인딩으 동시 실행이 가능하다.
각 포인트에 대한 자세한 설명은 생략하고, 대신 스케줄러 설정에서 다룰 수 있는 포인트들만 간단하게 짚겠다.[4]
- queueSort
- 스케줄링 큐의 파드들을 정렬한다.
- 한번에 한 플러그인만 들어갈 수 있다.
- preFilter
- 필터링을 들어가기 이전에 파드의 정보를 확인한다.
- 여기에서 아예 파드를 unschedulable 상태로 만들 수 있다.
- filter
- 파드가 배치될 수 없는 노드를 필터링하는 부분이다.
- postFilter
- 만약 배치될 수 있는 노드가 없다면 호출된다.
- 여기에서 파드를 schedulable이라고 세팅하면 다른 postFilter 플러그인들은 호출되지 않는다.
- preScore
- 스코어링 작업을 하기 이전에 정보를 전달해줄 수 있는 포인트
- score
- 스코어링을 하는 포인트이다.
- reserve
- 파드를 위해 예약된 자원 정보를 볼 수 있는 포인트
- 여기에 Unreserve 호출에 대한 정의를 해서 예약이 안됐을 때를 보는 것도 가능하다.
- permit
- 실제로 파드가 바인딩 되기 이전에 지연을 줄 수 있는 포인트
- preBind
- 바인딩이 되기 이전 필요한 작업을 수행할 수 있는 포인트
- bind
- 노드에 파드를 바인딩하는 포인트.
- 순서대로 호출되며 한 플러그인이라도 바인딩을 하면 다음 것들은 스킵된다.
- 최소한 하나는 무조건 필요하다.
- postBind
- 파드가 바인딩되고나서 정보를 볼 수 있는 포인트
- multiPoint
- 이건 실제 단계가 아니라 설정 상의 필드이다.
- 위에 여러 포인트 여러 개를 한꺼번에 호출할 때 쓴다.
설정법
스케줄러 설정은 형식이 꽤나 역동적이다.
그래서 전체적으로 짚을 만한 포인트를 위주로 정리를 한다.
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
percentageOfNodestoScore: 30 # 전체 노드 중 몇 퍼센트까지 골라내면 바로 스코어링 들어갈지.
profiles:
- schedulerName: default-scheduler
- schedulerName: no-scoring-scheduler
plugins:
preScore:
disabled:
- name: '*'
score:
disabled:
- name: '*'
pluginConfig:
- name: PodTopologySpread
args:
defaultConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway
defaultingType: List
- schedulerName: custom-scheduler
plugins:
score:
disabled:
- name: PodTopologySpread
enabled:
- name: MyCustomPluginA
weight: 2
- name: MyCustomPluginB
weight: 1
이런 설정 파일을 스케줄러 인자에 넣어서 커스텀 스케줄러 세팅을 하는 것이 가능하다.
profiles라는 필드에 여러 스케줄러를 설정할 수 있다.
이때 각 스케줄러는 schedulerName을 가진다(default만 있으면 굳이 안 써도 되긴 함).
그리고 plugins 필드에 각종 플러그인들이 스케줄링에 어떻게 쓰일지 명시해준다.
설정할 때는 plugins 필드에 각 포인트에 넣고 싶은 건 enabled, 빼고 싶은 건 disabled라고 해주면 된다.
score의 경우 점수를 매기는 것이기 때문에 보다시피 weight라는 필드는 적용될 순서를 나타내는 필드이다.
높은 점수를 가진 플러그인이 먼저 적용되게 된다.
pluginConfig에서는 각 플러그인 별 세팅을 하고 싶은 것들을 넣어주면 된다.
이건 각 플러그인마다 세팅법이 전부 다르니 문서를 참고하자.
실습 진행
스케줄링 기법들을 사용하는 건 전략을 어떻게 세우냐에 달렸다.
그런데 간혹 이것만으로는 부족할 때가 있다.
이럴 때는 결국 커스텀 스케줄러를 만드는 수밖에 없다.
커스텀 스케줄러를 사용함으로써 얻는 이점 중 가장 큰 것은 말 그대로 스케줄링을 커스텀할 수 있다는 것이다.
그러나 또다른 이점이 있는데, 바로 스케줄러의 부하를 줄일 수 있다는 것이다.
기본적으로 스케줄러를 HA한다고 해도 이들은 리더를 두는 방식으로 운용되기 때문에 결국 하나의 스케줄러가 부하를 감당한다.
이럴 때는 아예 스케줄러를 새로 두고, 이를 감당하는 프로세스를 별도로 분리하는 방식으로 부하를 줄이는 전략을 사용할 수 있다.
한번 커스텀 스케줄러를 만들어보자.
기본 스케줄러 정보 파악
먼저 기본스케줄러의 정보를 뜯어본다.
크게 알아야 할 것은 스케줄러가 클러스터에서 어떤 신원으로 활동하는지, 어떻게 설정되는지에 대한 것이다.

기본 스케줄러의 경우, 자체적으로 인증서를 가지고 있어 이를 기반으로 인증 인가가 가능하다.

스케줄러는 클러스터 내에서 system:kube-scheduler라는 신원을 가지고 있다.
k get clusterrolebindings.rbac.authorization.k8s.io system:kube-scheduler -oyaml

단순히 system:kube-scheduler란 클러스터롤을 받고 있으므로, 해당 클롤만 확인하면 스케줄러에 필요한 권한을 알 수 있다.
해당 클롤은 딱히 aggreagation이 없어서 그냥 마음 편하게 이용하면 될 듯하다.
apiVersion: v1
kind: ServiceAccount
metadata:
name: custom-scheduler
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: system:custom-scheduler
rules:
- apiGroups:
- ""
- events.k8s.io
resources:
- events
verbs:
- create
- patch
- update
- apiGroups:
- coordination.k8s.io
resources:
- leases
verbs:
- create
- apiGroups:
- coordination.k8s.io
resourceNames:
- custom-scheduler
resources:
- leases
verbs:
- get
- list
- update
- watch
- apiGroups:
- coordination.k8s.io
resources:
- leasecandidates
verbs:
- create
- delete
- deletecollection
- get
- list
- patch
- update
- watch
- apiGroups:
- ""
resources:
- nodes
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- pods
- configmaps
verbs:
- delete
- get
- list
- watch
- apiGroups:
- ""
resources:
- bindings
- pods/binding
verbs:
- create
- apiGroups:
- ""
resources:
- pods/status
verbs:
- patch
- update
- apiGroups:
- ""
resources:
- replicationcontrollers
- services
verbs:
- get
- list
- watch
- apiGroups:
- apps
- extensions
resources:
- replicasets
verbs:
- get
- list
- watch
- apiGroups:
- apps
resources:
- statefulsets
verbs:
- get
- list
- watch
- apiGroups:
- policy
resources:
- poddisruptionbudgets
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- persistentvolumeclaims
- persistentvolumes
verbs:
- get
- list
- watch
- apiGroups:
- authentication.k8s.io
resources:
- tokenreviews
verbs:
- create
- apiGroups:
- authorization.k8s.io
resources:
- subjectaccessreviews
verbs:
- create
- apiGroups:
- storage.k8s.io
resources:
- csinodes
verbs:
- get
- list
- watch
- apiGroups:
- storage.k8s.io
resources:
- volumeattachments
- storageclasses
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- namespaces
verbs:
- get
- list
- watch
- apiGroups:
- storage.k8s.io
resources:
- csidrivers
verbs:
- get
- list
- watch
- apiGroups:
- storage.k8s.io
resources:
- csistoragecapacities
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: system:custom-scheduler
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:custom-scheduler
subjects:
- kind: ServiceAccount
name: custom-scheduler
namespace: kube-system
이건 그냥 기본 스케줄러가 가지는 RBAC 권한을 그대로 복붙해주었다.
여기에 추가적으로 스케줄러의 기본 양식 파일을 참고하여 다음과 같이 양식 파일을 짰다.
apiVersion: v1
kind: Pod
metadata:
name: custom-scheduler
namespace: kube-system
labels:
component: kube-scheduler
tier: control-plane
spec:
containers:
- command:
- kube-scheduler
- --config=/etc/kubernetes/scheduler/scheduler-conf.yaml
- --v=11
image: registry.k8s.io/kube-scheduler:v1.32.2
name: kube-scheduler
resources:
requests:
cpu: 100m
volumeMounts:
- name: scheduler-config
mountPath: /etc/kubernetes/scheduler
readOnly: true
terminationGracePeriodSeconds: 30
serviceAccountName: custom-scheduler
priorityClassName: system-node-critical
tolerations:
- effect: NoExecute
operator: Exists
volumes:
- name: scheduler-config
configMap:
name: scheduler-config
내 스케줄러는 x509 인증을 하지 않을 것이기에, 서비스 어카운트를 따로 지정해주었다.
기본 스케줄러 양식은 빼기만 하고 크게 달라진 것은 없다.
아직 설정이 끝나지 않았는데, 바로 컨피그맵 구성이다.
apiVersion: v1
kind: ConfigMap
metadata:
name: scheduler-config
namespace: kube-system
data:
scheduler-conf.yaml: |
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
clientConnection:
kubeconfig: /etc/kubernetes/scheduler/kubeconfig
leaderElection:
leaderElect: false
profiles:
- schedulerName: custom-scheduler
plugins:
score:
enabled:
- name: NodeResourcesFit
weight: 2
disabled:
- name: NodeResourcesBalancedAllocation
- name: PodTopologySpread
pluginConfig:
- name: NodeResourcesFit
args:
apiVersion: kubescheduler.config.k8s.io/v1
kind: NodeResourcesFitArgs
scoringStrategy:
resources:
- name: cpu
weight: 1
- name: memory
weight: 10
type: MostAllocated
kubeconfig: |
apiVersion: v1
kind: Config
contexts:
- context:
cluster: kubernetes
namespace: kube-system
user: custom-scheduler
name: custom-scheduler@kubernetes
current-context: custom-scheduler@kubernetes
clusters:
- cluster:
certificate-authority: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
server: https://kubernetes.default.svc.cluster.local
name: kubernetes
users:
- name: custom-scheduler
user:
tokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
설정 파일을 동적으로 구성할 수 있도록 컨피그맵으로 스케줄러 설정파일을 만들어 관리한다.
근데 스케줄러에는 컨피그 파일의 변경을 동적으로 감지하고 리로드하는 기능이 없어서 결국 다시 시작하긴 해야 한다.
kubeconfig 파일을 넣어 명확하게 파드에 지정한 서비스어카운트의 신원을 이용해 api 서버와 통신을 하게 했다.
이 kubeconfig를 전체 config 양식 상에서 clientConnection.kubeconfig 필드에 kubeconfig 파일 경로를 써주면 된다.
kubeconfig에서는 유저 신원 검증을 위해 서비스 어카운트 토큰을 사용하도록 했는데 tokenFile 필드로 경로를 넣어주면 해당 파일의 토큰을 가져와 인증에 사용한다.

권한 문제가 몇 개 뜨는데, 로그를 보고 세팅했던 권한 양식에 계속 추가해주는 식으로 세팅했다.
기본 확인

제대로 동작하고 있으니, 실질적으로 이런 방법은 관리형 쿠버네티스에서도 사용할 수 있는 방법이라고 봐도 무방하겠다.
여력이 된다면 eks 환경에서도 테스트를 진행해볼 듯 싶다.

로그를 보면 많은 정보를 알 수 있다.
일단 어떤 플러그인들이 사용되는지는 물론이고 각 스케줄링 플러그인의 가중치가 어떻게 되는지도 나온다.

또한 기본으로 설정되는 플러그인들의 설정 정보도 출력된다.

재밌는 정보들이 생각보다 많다.
일단 기본 리소스 패킹 전략은 MostAllocated로 설정되어 있어서, 최대한 자원이 많이 사용되는 노드에 높은 점수를 부여한다.
기본 테스트
apiVersion: v1
kind: Pod
metadata:
name: default-schedule
spec:
containers:
- name: myapp
image: nginx:latest
resources:
requests:
# cpu: 100m
memory: 200Mi
terminationGracePeriodSeconds: 1
schedulerName: custom-scheduler
단순하게 파드를 만들고, 사용할 스케줄러를 명시해준다.
만약 탐지되지 못한 스케줄러를 사용한다면 파드는 펜딩 상태로 머물게 된다.

제대로 스케줄러가 작동한다면 위와 같이 스케줄링을 진행했다는 로그가 남는다.

다른 글에서는 점수가 어떻게 매겨졌는지도 로그가 남길래 어떻게 하는 건가 하고 봤더니, 로그 레벨을 11까지 올려서 보더라..[^6]
로그가 엄청 커지는 걸 감안하고 보면 이렇게 점수도 확인할 수 있다.
커스텀 리소스를 활용해 스케줄링하기
이제 본격적으로 내가 의도한 대로 스케줄링이 동작하도록 해본다.
미리 말하지만 이 실습을 실패했다.
실패한 채로 실습이 종료되었으므로, 사투했던 흔적을 정리하지 않고 기록한다.
전략
일단 스케줄러가 어떻게 동작해야 할지 먼저 정의해보자.
- custom.resource/bbb가 있는 자원에는 배치되지 않는다. - 필터링
- custorm.resource/aaa가 많이 사용된 곳에 배치되게 한다. - 스코어링
- custorm.resource/aaa가 많은 곳에 배치되게 한다. - 스코어링
간단한 정도로는 이 정도로 전략을 짜보았다.
이를 위해 현재 사용하는 노드에 먼저 커스텀 리소스를 등록해야 한다.
- 마스터 노드
- aaa 5개
- aaa 3개 사용됨
- 워커 노드 1
- aaa 10개
- 워커 노드 2
- aaa 12개
- bbb 1개
처음에는 이 상태로 시작하여 aaa를 요청하는 첫번째 파드가 마스터 노드에 배치되게 한다.
그 다음, 직접 워커노드1에 aaa를 4개 사용하는 파드를 배치하고 다시 파드를 배치한다.
이때는 마스터 노드와 워커노드1이 aaa를 똑같이 사용하므로 aaa가 많은 워커 노드 1에 파드가 배치되면 성공이다.
사전 세팅
curl --header "Content-Type: application/json-patch+json" \
--request PATCH \
--data '[{"op": "add", "path": "/status/capacity/example.com~1foo", "value": "5"}]' \
http://k8s-master:8080/api/v1/nodes/k8s-node-1/status
이런 식으로 커스텀 리소스를 노드에 넣어, 이게 최대한 많이 사용된 곳에 파드가 배치되게 할 것이다.[5]
실제 gpu라면 아마 gpu 자원을 디바이스 플러그인으로 관리하는 경우가 많을 텐데, 이걸 커스텀해서 만드는 것도 가능하다.
kubectl patch nodes worker1 --type='json' -p='[{"op": "add", "path": "/status/capacity/custom.resource~1aaa", "value":"10"}]'
curl로 못할 건 없지만, 귀찮게 인자 추가해서 넣고 싶지도 않고 kubectl에서도 patch를 지원해보니 이걸 활용해본다.

는 실패..
proxy를 임시로 세워서 하는 방법이 있긴 한데, 별로 하고 싶은 방법은 아니다.[6]
k krew install edit-status
대신 이를 지원해주는 플러그인을 찾아서 이것을 활용해본다.[7]

음.. 이걸로도 안 바뀌는 것 같다..?
kubectl patch nodes worker1 --subresource='status' --type='json' -p='[{"op": "add", "path": "/status/capacity/custom.resource~1aaa", "value":"10"}]'

뒤늦게 알았는데, 서브리소스 중 status를 바꿀 때는 이런 식으로 따로 명시를 해주어야 한다.
보통 status가 사용자의 수정에 영향을 받지 않는다는 것은 알았지만, 이렇게 해서 세팅할 수 있다는 것은 또 처음 알았다.
kubectl patch nodes master1 --subresource='status' --type='json' -p='[{"op": "add", "path": "/status/capacity/custom.resource~1aaa", "value":"5"}]'
kubectl patch nodes worker2 --subresource='status' --type='json' -p='[{"op": "add", "path": "/status/capacity/custom.resource~1aaa", "value":"12"}]'
kubectl patch nodes worker2 --subresource='status' --type='json' -p='[{"op": "add", "path": "/status/capacity/custom.resource~1bbb", "value":"1"}]'
일단 기본적인 노드 작업을 마친다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: aaa-in-master
labels:
app: aaa-in-master
spec:
selector:
matchLabels:
app: aaa-in-master
replicas: 3
template:
metadata:
labels:
app: aaa-in-master
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: node-role.kubernetes.io/control-plane
operator: Exists
tolerations:
- key: "node-role.kubernetes.io/control-plane"
operator: "Exists"
containers:
- name: request-extra-resource
image: nginx:latest
resources:
requests:
custom.resource/aaa: 1
limits:
custom.resource/aaa: 1
마스터 노드에 사전 배치할 워크로드는 이런 식으로 세팅했다.
톨러레이션을 주어 마스터 노드에 배치될 수 있도록 했고, 노드 어피니티를 통해 컨트롤 플레인인 노드에만 배치되도록 만들었다.

제대로 배치된 것을 확인할 수 있다.
본격 실습 - 실패
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
clientConnection:
kubeconfig: /etc/kubernetes/scheduler/kubeconfig
leaderElection:
leaderElect: false
profiles:
- schedulerName: custom-scheduler
plugins:
score:
enabled:
- name: NodeResourcesFit
weight: 10
disabled:
- name: NodeResourcesBalancedAllocation
- name: PodTopologySpread
pluginConfig:
- name: NodeResourcesFit
args:
apiVersion: kubescheduler.config.k8s.io/v1
kind: NodeResourcesFitArgs
ignoredResources:
- cpu
- memory
scoringStrategy:
resources:
- name: custom.resource/aaa
weight: 10
type: MostAllocated
이제 스케줄링 설정을 해줘야 한다.
노드 리소스의 상태를 강하게 점수 매기도록 했고, cpu와 메모리는 고려하지 않는 채로 점수를 매기도록 설정했다.
근데 한 가지 간과한 것이, 노드 필터링을 할 때 자원을 이용할 수 있을 것이라 생각했다.
그러나 기본 플러그인 중에서는 이러한 기능을 제공하는 것이 없어, 이걸 고려하게 하려면 커스텀 스케줄러를 만드는 정도가 아니라 스케줄링 플러그인까지 개발해야 한다...
당장 할 시간은 조금 부족해서 그냥 노드에 라벨을 붙이고 파드 스펙에 해당 노드를 피하도록만 세팅했다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: aaa-pod
labels:
app: aaa-pod
spec:
selector:
matchLabels:
app: aaa-pod
replicas: 1
template:
metadata:
labels:
app: aaa-pod
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: no-schedule
operator: DoesNotExist
tolerations:
- key: "node-role.kubernetes.io/control-plane"
operator: "Exists"
containers:
- name: aaa-pod
image: nginx:latest
resources:
requests:
custom.resource/aaa: 1
limits:
custom.resource/aaa: 1
schedulerName: custom-scheduler
시험할 워크로드는 이렇게 생겼다.
말했듯이 워커 노드 2에는 배치되지 않도록 노드 어피니티에 워커 노드 2만 가지고 있는 라벨을 넣어주었다.
두번째로 배포를 할 때는 단순하게 이 친구를 스케일링 해주면 된다.

첫번째 파드는 압도적인 점수 차로 마스터 노드에 배치됐다.
그 다음, 워커 노드 1에 대충 4개를 활용하는 파드를 하나 띄우고 스케일링을 진행했다.

예상치 못한 상황.. 근소하게 차이가 좁혀질 거라 생각했건만, 생각보다 간극이 크게 줄지 않았다.
MostAllocated 전략은 노드에 자원이 채워진 정도도 고려하는 것으로 보인다.
RequestedToCapacityratio만 그런 줄 알았는데..
본격 실습 - 재도전도 실패..
처음 생각한 전략의 의미를 다시금 생각해봤다.
일단 실질적으로 현재 기본으로 주어진 플러그인을 커스텀하는 식의 설정에서는 사용할 수 있는 플러그인이 NodeResourceFit밖에 없다.
이 플러그인은 자원이 많이 할당된 곳, 혹은 적게 할당된 곳에 점수를 높게 주는 식으로 밖에는 세팅을 하지 못한다.
이 중간 사이에서 비율을 세팅하고자 할 때 RequestedToCapacityRatio를 활용할 수 있기는 하다.
그러나, 결국 요지는 하나의 선형 함수로만 사용하는 꼴이고, 이 플러그인 만으로는 내가 생각한 두가지 스코어링 전략을 만족시킬 수 없다.
그렇다면 이런 방식을 생각해볼 수 있다.
일단 처음 스코어링 기준인 자원이 많이 쓰인 곳에 파드 배치하기, 이것은 기존처럼 NodeResourceFit 플러그인으로 적용할 만한 기준이다.
그 이후 두번째 기준인 자원이 많은 곳에 배치하기는 조금 의미를 바꿔, 고르게 자원을 배치하려는 것으로 생각해볼 수 있다.
그렇다면 NodeResourceBalacedAllocation 플러그인을 사용할 수 있지 않을까?
기본적으로는 노드를 채우는 것에 중점을 두도록 점수가 부여되나, 채우다가 점차 고르게 배치하는 쪽으로 방향을 틀게 되도록 가중치를 배치하는 것이다.
직접 하다보니 왜 저번 KKCD에서 발표자 분이 커스텀 스케줄러를 개발하셨는지 확 체감이 된다 ㅋㅋ

처음에는 역시 마스터 노드에 배치되도록 점수가 부여된다.
근데 조금 싸한 것이 밸런스쪽 점수가 그대로다..

세팅을 하고 두번째 파드를 배치했는데, 이번에도 밸런스에 대한 점수는 그대로이다.
그렇다면 아무래도 이건 내가 플러그인의 의미를 잘못 해석한 것일 가능성이 높다.
이건 노드 간 자원 분배를 신경쓰는 플러그인이 아니라, 어떤 노드에 배치했을 때 파드가 요구한 자원들이 밸런스있게 소모되는지를 따지는 플러그인인 것이다.
그렇다면 내가 기대한 전략에 사용할 수는 없다.
여기에서 한가지 더 생각이 든 것은, 파드 어피니티를 활용하는 전략이다.
조금씩 가중치를 수정해가면서 하면 할 수 있겠다는 생각은 드는데, 이것까지 하기에는 시간이 조금 부족해서 현재 실습은 여기에서 마무리하려고 한다.
아쉽지만 커스텀 리소스를 등록하는 방법, 그리고 커스텀 스케줄러를 만드는 방법에 대한 지식과 경험을 쌓은 것만으로 만족해야 할 듯하다.
자원 삭제
kubectl patch nodes worker2 --subresource='status' --type='json' -p='[{"op": "remove", "path": "/status/capacity/custom.resource~1bbb"}]'
kubectl patch nodes worker2 --subresource='status' --type='json' -p='[{"op": "remove", "path": "/status/capacity/custom.resource~1aaa"}]'
kubectl patch nodes worker1 --subresource='status' --type='json' -p='[{"op": "remove", "path": "/status/capacity/custom.resource~1aaa"}]'
kubectl patch nodes master1 --subresource='status' --type='json' -p='[{"op": "remove", "path": "/status/capacity/custom.resource~1aaa"}]'
실습이 끝나면 만들었던 커스텀 자원은 싹 없애주자.
결론
쿠버네티스의 다양한 스케줄링 기법을 사용하여 자원을 효과적으로 활용하는 것은 운영자의 기본 역량일 것이다.
다만 클러스터가 커지고 자원이 세분화될수록 기본 스케줄러의 기능으로는 부족하다고 느끼는 지점이 생길 수 있는데, 이럴 때는 커스텀 스케줄러를 만드는 것을 충분히 고려해볼 만하다.
실패한 실습에 대한 회고
사실 처음에 구상한 전략이 현실적인 운영 케이스에 맞는가에 대한 고려도 해봐야한다.
가능한 자원이 많이 사용되고 있는 곳에 꽉꽉 파드를 배치하는 것은 충분히 가능한 전략이다.
특히나 gpu처럼 단위가 정수로 나눠떨어지는 자원이라면 그렇다.
그러나 그러면서도 개수가 비슷해지면 자원이 많은 곳으로 배치되도록 한다?
어감이 조금 이상하다고 느껴진다.
차라리 이런 전략이면 조금 말이 되는 것 같다.
기본적으로는 자원이 많은 곳으로 파드를 배치한다.
이때부터 자원이 많이 사용되는 곳에 점수를 높게 주는 것이다.
이 전략은 충분히 말이 되는데, 이걸 처음에 생각하지 않는 것은 아니다.
다만 스케줄러의 점수가 구해지는 방식을 구체적으로 알기 전까지는 사실 어차피 스케줄러가 알아서 자원이 많은 노드를 골라줄 것이라고 생각했기에 이 전략은 그냥 MostAllocated 전략과 동치라고 생각했을 뿐이다.
그러나 막상 점수가 산정되는 것을 보니, 오히려 이런 전략은 직접적으로 스케줄러를 커스텀해야만 이룰 수 있는 전략이다.
다음에 시간이 난다면 이 전략을 집중적으로 파볼까 한다.
이전 글, 다음 글
다른 글 보기
| 이름 | index | noteType | created |
|---|---|---|---|
| 1W - EKS 설치 및 액세스 엔드포인트 변경 실습 | 1 | published | 2025-02-03 |
| 2W - 테라폼으로 환경 구성 및 VPC 연결 | 2 | published | 2025-02-11 |
| 2W - EKS VPC CNI 분석 | 3 | published | 2025-02-11 |
| 2W - ALB Controller, External DNS | 4 | published | 2025-02-15 |
| 3W - kubestr과 EBS CSI 드라이버 | 5 | published | 2025-02-21 |
| 3W - EFS 드라이버, 인스턴스 스토어 활용 | 6 | published | 2025-02-22 |
| 4W - 번외 AL2023 노드 초기화 커스텀 | 7 | published | 2025-02-25 |
| 4W - EKS 모니터링과 관측 가능성 | 8 | published | 2025-02-28 |
| 4W - 프로메테우스 스택을 통한 EKS 모니터링 | 9 | published | 2025-02-28 |
| 5W - HPA, KEDA를 활용한 파드 오토스케일링 | 10 | published | 2025-03-07 |
| 5W - Karpenter를 활용한 클러스터 오토스케일링 | 11 | published | 2025-03-07 |
| 6W - PKI 구조, CSR 리소스를 통한 api 서버 조회 | 12 | published | 2025-03-15 |
| 6W - api 구조와 보안 1 - 인증 | 13 | published | 2025-03-15 |
| 6W - api 보안 2 - 인가, 어드미션 제어 | 14 | published | 2025-03-16 |
| 6W - EKS 파드에서 AWS 리소스 접근 제어 | 15 | published | 2025-03-16 |
| 6W - EKS api 서버 접근 보안 | 16 | published | 2025-03-16 |
| 7W - 쿠버네티스의 스케줄링, 커스텀 스케줄러 설정 | 17 | published | 2025-03-22 |
| 7W - EKS Fargate | 18 | published | 2025-03-22 |
| 7W - EKS Automode | 19 | published | 2025-03-22 |
| 8W - 아르고 워크플로우 | 20 | published | 2025-03-30 |
| 8W - 아르고 롤아웃 | 21 | published | 2025-03-30 |
| 8W - 아르고 CD | 22 | published | 2025-03-30 |
| 8W - CICD | 23 | published | 2025-03-30 |
| 9W - EKS 업그레이드 | 24 | published | 2025-04-02 |
| 10W - Vault를 활용한 CICD 보안 | 25 | published | 2025-04-16 |
| 11W - EKS에서 FSx, Inferentia 활용하기 | 26 | published | 2025-04-18 |
| 11주차 - EKS에서 FSx, Inferentia 활용하기 | 26 | published | 2025-05-11 |
| 12W - VPC Lattice 기반 gateway api | 27 | published | 2025-04-27 |
관련 문서
| 이름 | noteType | created |
|---|---|---|
| PDB | knowledge | 2024-08-31 |
| 스케줄링 | knowledge | 2025-01-12 |
| Quality of Service | knowledge | 2025-03-09 |
| 어피니티 | knowledge | 2025-04-18 |
| Affinity | knowledge | 2025-03-19 |
| Topology Spread Constraints | knowledge | 2025-03-19 |
| Scheduling Gates | knowledge | 2025-03-19 |
| kube-scheduler | knowledge | 2025-03-19 |
| 테인트, 톨러레이션 | knowledge | 2025-03-19 |
| 스케줄링 제어 | knowledge | 2025-03-20 |
| 파드 중단 | knowledge | 2025-03-20 |
| 쿠버 스케줄러 시뮬레이터 소개 | knowledge | 2025-04-08 |
| E-nodeName으로 스케줄링 실습 | topic/explain | 2025-03-19 |
참고
https://kubernetes.io/docs/concepts/scheduling-eviction/assign-pod-node/ ↩︎
https://kubernetes.io/docs/tasks/configure-pod-container/assign-pods-nodes/ ↩︎
https://kubernetes.io/docs/concepts/scheduling-eviction/scheduling-framework/ ↩︎
https://kubernetes.io/docs/reference/scheduling/config/#scheduling-plugins ↩︎
https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ ↩︎
https://kubernetes.io/docs/tasks/administer-cluster/extended-resource-node/ ↩︎